After a long hiatus I've found the time to update PicasaWebDownloader. If you're using the tool, there's a bunch of compelling reasons why you'd probably want to update. As always, code is included and feedback is welcome.
Update (22-Sep-08): As Peter Kasting from the Chromium team (I think?) mentioned in the comments, this hack is unnecessary. Simply go to google.com, click on Google In English, restart Chrome and wait about 10 seconds, which will result in the desired behavior. Chrome is amazing. It really is. Ridiculously fast, ridiculously compact (less than 0.5MB installation!†) and seems to just work, which is truly astonishing for a product of this caliber, particularly the first version thereof. The one obvious deficiency I could find was that it decided on google.co.il (the Israeli version of the Google homepage) as my default search provider, whereas my preference is for the regular English version on google.com. The search provider settings cannot be changed and do not respect the homepage's cookie (click on Google in English once and you're supposed to be done with it). Apparently it uses a {google:baseURL} macro which does not appear to be defined anywhere, and the only workaround I could find was: - Start->Run
- notepad "%userprofile%\AppData\Local\Google\Chrome\User Data\Default"
- Look for the line starting with "search_url": (for me it was line 8)
- Replace {google:baseURL} with http://www.google.com/
The damn thing still changes the setting every now and then. I'll file a bugreport with Google, but this should suffice in the meantime (search results rendered right-to-left can drive me up the wall). Update: As Shy noted in the comments, the installer actually is a downloader, I just didn't notice the first time because I was doing other things while it was starting up. In practice, though, it's annoying as hell, particularly if you're on a slow pipe. Bad Google!
Update (11 March 2009): Microsoft has retired FolderShare in favor of Windows Live Sync. It’s basically the same service, except they’ve significantly increased the file limit per library and finally added full Unicode support. Now that my two major gripes with the service are resolved I’m perfectly happy with Sync, and it’s free to boot! I have a very large collection of music files, easily 70GB with thousands of files (those lossless rips can be quite space-consuming). I listen to music both at home and at work, and don't want to go through the trouble of synchronizing these collections manually. In fact, I would like a service that fulfills the following requirements: - Easy to set up;
- Works across NAT, preferably with UPnP support;
- Full Unicode support;
- No artificial limit on library size;
- Not required, but definitely advantageous:
- Free;
- Low memory and CPU overhead;
- Libraries are accessible over the web;
- Some sort of online backup solution
The NAT support is an absolute must, as I have little or no control over the firewall at work. Unicode support may sound like a trivial requirement, but as you'll see most solutions do not properly support Unicode. My collection contains albums in multiple languages, including Hebrew, Japanese and Norsk, but even English albums can cause issues (Blue Öyster Cult, for example). I've tested the following solutions:
Microsoft FolderShare (now Windows Live Sync, see update above) Although this is one of the oldest players in the game (the company was bought out by Microsoft in 2005) it hasn't seen any visible improvement in a very long time. Despite the apparent dormant development, the service itself works well and is very consistent and reliable. What separates FolderShare from any other solution I've tested is a very user-centric design: any reasonably literate computer user (read: knows what files are and can double-click on an install button) should be able to set up a FolderShare account and start synchronizing files literally in minutes. Once set up the service simply works; other than the disadvantages which I'll enumerate momentarily, I've had absolutely zero problems with the service in over a year of use (well, to be honest there was a highly-publicized two-week service outtage over a year ago, but it's been hassle-free before and since). FolderShare fails in two specific ways: it's limited to 10,000 files per library (I think there's a limit on the number of libraries supported, but I've never come close to it), and it does not properly support Unicode. This means that files with characters outside the ANSI character set and machine codepage simply do not get synchronized. Other than that its interface is amazingly limited with very few customizable options, but in my opinion this isn't really an issue because the software simply does its job really well. With these disadvantages in mind, I wouldn't hesitate to recommend FolderShare to English speakers (or ones that do not make use of non-Latin file names), but the rest of us will have to look elsewhere. With Unicode support I'd definitely go back to FolderShare though, it's an excellent product. PowerFolder Touted as an open-source file synchronization solution, PowerFolder utterly failed to impress me; it appears to be a very powerful solution, but consequently suffers from a very cluttered UI that's hard to grok. I wouldn't recommend this service to casual users, and it wasn't trivial for me (as a software developer) to figure out either. I installed a trial version of PowerFolder Pro on both machines, but once I got past the strange UI idioms I just couldn't get the software to work reliably. I managed to send an invitation from one machine to the next (synchronized directories in PowerFolder do not appear to be centrally managed), but couldn't figure out how to get them to sync reliably nor how to resolve file conflicts. Finally, the client software is a real memory hog. BeInSync Fairly similar to PowerFolder (with additional online backup features on Amazon's S3 storage service), BeInSync is a commercial product that appears to provide all of the features I require. The service was fairly easy to set up, although not nearly as streamlined as FolderShare. I got my directories to synchronize properly and was relieved to find that Unicode is fully supported by this product. Despite the promising start, my experience with this product was far from satisfactory: the client UI is incredibly slow and non-responsive. Other than general slowness in rendering speed and bizarre UI idioms (for example, the only way to get a reasonable status display is via the View menu), resolving synchronization conflicts can easily take 30 seconds per file with no batching capabilities at all. On top of that the client software is a major resource hog, easily taking up 60MB and more resident memory, and for a reason I couldn't figure out I could see 3-9MB per second I/O activity from the client although it exhibits no synchronization activity. To add insult to injury, the uninstall program requested that I restart my computer - nitpicking, I know, but what the hell? Having tested three different services I'm sorely tempted to go back to FolderShare and figure our a manual synchronization scheme for the Unicode files. The other alternative is a homebrew VPN+robocopy/rsync/SyncToy solution which I'd prefer to avoid. I'm rather surprised that it's so hard to find hassle-free synchronization services so late in the game...
Apparently Vorbis (.ogg) files are not all that commonplace, and some popular web servers (at least IIS7) aren't configured to handle them by default. Under the assumption that it's a case of missing MIME type I send a support request to GoDaddy (my web host of choice), who were pleasantly responsive and even helpful. IIS 7.x supports configuration of mime-types on the application or virtual directory level by including the following lines in a Web.config file at the root of said directory: <system.webServer>
<staticContent>
<mimeMap fileExtension=".ogg" mimeType="audio/ogg" />
</staticContent>
</system.webServer>
After making the change, all .ogg file links within this site are now accessible (this particularly pertains to the Defender of the Crown links).
This guy hooked up an old Sinclair ZX Spectrum to a bunch of crappy hardware (a hard drive array, an old dot matrix printer and a scanner) and got them to play an amusing (though still impressive) approximation of Radio Head's "Nude". Here's to a bigger geek than I can ever hope to be! 
Because the Java language lacks delegates, anonymous classes are prevalent as a syntactic replacement. Non-static nested classes are also often used in the language, a feature which is conspicuously absent from C#, albeit far less necessary with that language. This brings me to the following language caveat. This may seem a contrived example, but it's a simplification of an actual issue I've encountered in the last few days. Suppose you have a generic base class, call it BaseClass<U>, which you extend with an anonymous class. Lets also assume that the extended class spawns a thread that needs to access the BaseClass<U> state: class BaseClass<U> {
void getState() {}
}
class Test {
public void test() {
final BaseClass<String> instance = new BaseClass<String>() {
public void invokeStatefulThread() {
// Create our runnable
final Runnable threadCode = new Runnable() {
public void run() {
/* 1 */ getState();
/* 2 */ this.getState();
/* 3 */ super.getState();
/* 4 */ BaseClass.this.getState();
/* 5 */ BaseClass<String>.this.getState();
}
};
new Thread( threadCode ).start();
}
};
instance.invokeStatefulThread();
}
}
I'll spare you the guessing game. Here's what happens with each of the five invocations of getState():
- Compiles and behaves as expected.
- Obviously won't compile; this points to the Runnable.
- Obviously won't compile; the superclass of a Runnable is Object.
- Although this is the correct raw class, it won't compile because "No enclosing instance of the type BaseClass<U> is accessible in scope", even though the raw type should still be accessible and U can be inferred.
- Although this appears to be the correct fully-qualified form, this does not compile with a "Syntax error on token(s), misplaced construct(s)" error.
The Java language specification section on "qualified this" is very brief and does not mention generics at all (does "class name" include bounded type parameters?). Oddly enough, moving the class declaration outside of the test method actually lets 4 compile -- if there's a clue there, I haven't figured it out yet.
I still haven't found a syntactically-correct way to access BaseClass<string>.this, other than placing it in a temporary variable outside of the Runnable declaration. I searched yesterday for a couple of hours with no obvious solution in sight. Ideas are more than welcome!...
In addition to the wide press coverage on US-oriented technology sites we've seen coverage from two major Israeli news providers (Hebrew only, for now): Calcalist and TheMarker. Now comes the fun part; Delver is still borderline-alpha. We've been working hard testing and tweaking it, and getting a system of this complexity working in good order on a ridiculously short schedule feels astounding. I sincerely believe the Delver premise is a solid one, and we're giving you a mere inkling of what's in store for the concept; now all we have to do is work harder, growing along with the product and slowly but surely realizing its full potential. The brilliant part? Beyond the dreams of rich and fame, this product already is useful; with relentless improvements it may yet become as indispensable a tool to Internet denizens as Google, Wikipedia and Facebook are today.
An alpha version of our search engine is now open for all users! 
We've been working towards this day for the past year, building a complete and functional search engine from scratch on a completely original premise. I'm both amazed and proud of the work done by the various teams, and I'm still can't believe we've managed to pull this off in so little time. Launching the search engine publicly seems like a great way to celebrate the year I've been working for Delver (as of July 1st). Mind you, the service is still new and we're hammering away at the kinks, but so far we've had overwhelmingly positive press coverage and the various comments are sincerely flattering. Here's to another amazing year! As an aside, we're got openings on my team (search back-end) for extremely talented software developers who are interested in building performance-driven, robust back-end software in a variety of technologies. Interested? Contact me for details at tomer@delver.com!
After figuring out the problem with the old dasBlog permalinks I had to figure out a way to convert all existing links in my blog to the new format. Lately whenever I need a script I try and take the opportunity to learn a bit of Python, so it took an hour or two to write the conversion script. Here it is; if you want to use this for your own copy of dasBlog, change the "domain" global variable to wherever your blog is located and run this from your ~/Content directory (you can also download the script here): #!/usr/local/bin/python
#
# convert_permalinks.py
# Quick and dirty permalink converter for dasBlog content files
#
# Tomer Gabel, 22 June 2008
# http://www.tomergabel.com
#
# This code is placed in the public domain (see http://creativecommons.org/licenses/publicdomain/)
from __future__ import with_statement
import os
import glob
import re
import urllib
# Static constants
domain = 'tomergabel.com'
href_lookup = re.compile( 'href="(http:\/\/(www\.)?' + re.escape( domain ) + '/[^"]*\+[^"]*?)"' )
# Globals
conversion_map = {}
# Takes a URL and removes all offensive characters. Tests the new URL for validity (anything other than a 404 error is considered valid).
# Returns a tuple with the converted URL and a boolean flag indicating whether the converted URL is valid or not.
def convert( url ):
new_url = url.replace( "+", "" )
# Check URL validity
valid = True
try:
resp = urllib.urlopen( new_url )
resp.close()
except:
valid = False
return [ new_url, valid ]
# Processes the source file, converts all URLs therein and writes it to the target file.
def process( source_file, target_file ):
with open( source_file, "r" ) as input:
source_text = input.read()
conv_text = source_text
match_found = False
for matcher in href_lookup.finditer( source_text ):
if ( matcher != None ):
match_found = True
original_url = matcher.group( 1 )
print "\tConverting permalink " + original_url
if not conversion_map.has_key( original_url ):
conversion_map[ original_url ] = convert( original_url )
conversion = conversion_map[ original_url ]
if conversion[ 1 ]:
print "\tConversion successful, new URL: " + conversion[ 0 ]
conv_text = conv_text.replace( original_url, conversion[ 0 ] )
else:
print "\tConversion failed!"
# Write out the target file
if match_found:
with open( target_file, "w" ) as output:
output.write( conv_text )
# Entry point
for file_name in glob.iglob( "*.xml" ):
print "Processing " + file_name
process( file_name, file_name + ".conv" )
What a stroke of luck! With more and more sites foregoing captchas, I was starting to think weird-ass captchas are a thing of the past. Fortunately trusty old RapidShare brought me to task: 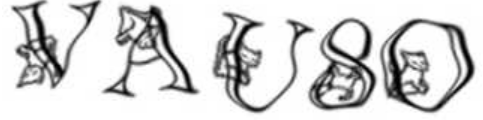
Apparently not only am I meant to figure out the convoluted glyphs (it took me a while to figure out that there are no numbers -- their G looks exactly like a 6, O and 0 look the same etc.), but I'm supposed to match only the letters connected to a cat. Conceptually amusing, but what the hell? Can you tell me which of the above are cats? Is it reasonable to expect someone to spend more than about 5 seconds on a captcha? Oddly enough I re-entered the link a little while later to discover the amazing RapidShare feature called "Happy Hour": 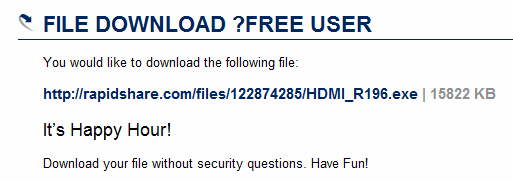
And I'm just left scratching my head.
|